Motivation
As an aspiring data scientist seeking his debut role, I’ve pored over an excess of a hundred job listings for data science positions, including those of data analyst and data engineer. This extensive exposure has enabled me to discern recurring patterns and familiar structures in their composition. And recently there’s this hot new tool that recently came out called ChatGPT (perhaps you’ve heard of it), I wanted to harness the power of OpenAI GPT models to mine these descriptions for actionable insights. My undertaking involved utilizing GPT APIs to comprehensively analyze the job postings of recent times, enabling me to scope the current data-tech job market landscape. Moreover, I shed light on the abilities and constraints of the present GPT models, up to GPT-3.5 turbo (unfortunately, my access to GPT-4 is still pending at the time of writing this article).
Anatomy of a job description (JD)
The format of a job description varies a lot since it is typically manually written by the hiring manager or HR department. It can be brief and concise, or long and convoluted.
The typical job description can be broken down into 3 main components, usually presented in the following order:
- Company or job summary
- Describes the purpose of the company as well as the company culture.
- This is unique to the company
- Often not very useful for assessing the candidate fit for a job - Responsibilies or duties
- List of all the responsibilities and essential functions of the job, usually in point form.
- Sometimes list specific tools or tech stacks that you’ll be using
- It can be very vague or very specific. In general, it’s hard to summarize all the expected duties, since even employers not sure what they want from you. - Qualifications or requirements
- List of all the qualifications they want from candidate, also in point form
- This section is the excplicitly states what they want from you, and should be the first part you look at to determine your fit.
These 3 components of the job description is almost always present, even if not presented explicitly. Often you’ll see subheading such as “what will you do” for responsibilities section or “what you’ll need” for qualifications section, or other variants of subheadings, but they really mean the same thing.
There are, of course, other additional information about the job such as salary, benefits, company culture, values, equity and inclusivenss actions, etc. I find that these sections are not always included in the JD, especially for smaller companies. So just to be consistent with most JDs posted, I only consider the 3 main components described above.
How to Use ChatGPT for Job Description
One of the most common and effective use cases of GPT is text summarization. This is especially useful for extracting the core skills required for the job, or other qualifiers such as education or years of experience. I won’t go into detail about how to use the api, since this can be found in official documentation https://platform.openai.com/docs/.
Here is an example of how it can be used to extract the qualifications section. First copy and paste the job description and added the prompt to tell the model how to summarize the jd. Note that the prompt can be added at the beginning or end of the job description. The prompts I used are:
- “What are the responsibilities of the job? Express the answer in point form.”
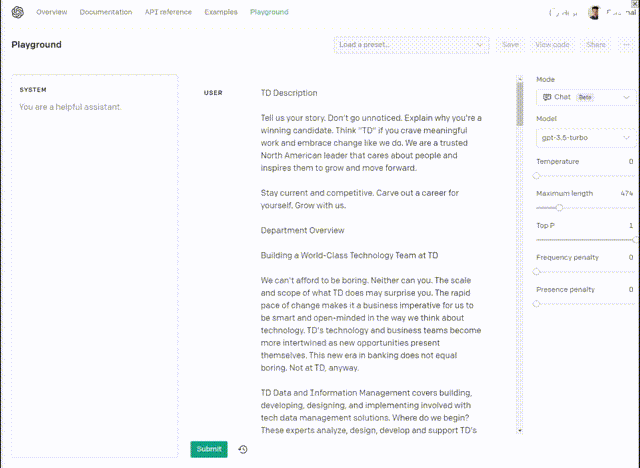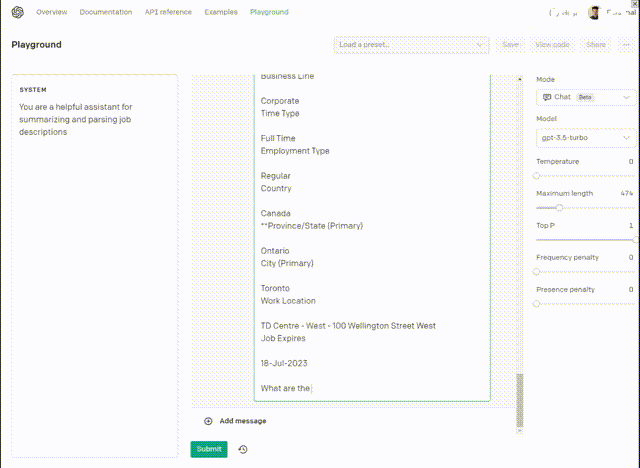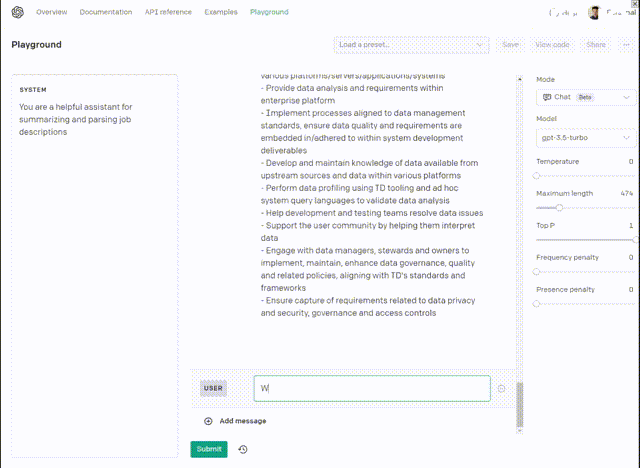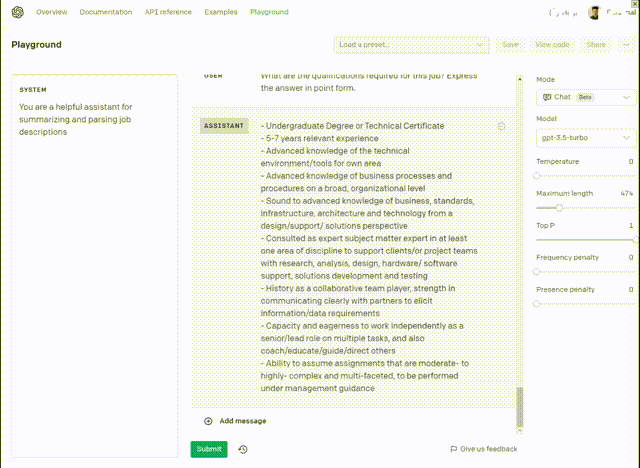
- “What are the qualifications for this job? Express the answer in point form.”
- “What are the tech skills required for this job? Express the answer in point form.”

Output from text-davinci-003 model
Prompt: "What are the responsibilities of the job? Express the answer in point form."
- Elicit, analyze, interpret business and data requirements to develop complete business solutions, includes data models (entity relationship diagrams, dimensional data models), ETL and business rules, data life cycle management, governance, lineage, metadata and reporting elements.
- Apply automation and innovation on new and on-going data platforms for those development projects aligned to business or organizational strategies.
- Design, implement reporting platforms (e.g. modeling, ETL, BI framework) and complex ETL frameworks that meet business requirements.
- Work with technology/project teams to understand the business meaning of data, provide analysis and requirements so that data design is fully understood and the development initiatives are in line with intended design and standards.
- Deliver business or enterprise data deliverables (that adhere to enterprise frameworks) for various platforms/servers/applications/systems.
- Provide data analysis and requirements within enterprise platform (e.g. Hadoop).
- Implement processes aligned to data management standards, ensure data quality and requirements are embedded in/adhered to within system development deliverables.
- Develop, maintain knowledge of data available from upstream sources and data within various platforms.
- Perform data profiling using TD tooling and ad hoc system query languages to validate data analysis.
- Help development and testing teams resolve data issues.
- Support the user community by helping them interpret data.
- Engage with data managers, stewards and owners to implement, maintain, enhance data governance, quality and related policies, aligning with TD's standards and frameworks.
- Ensure capture of requirements related to data privacy and security, governance and access controls.
- Respect TD's technology delivery practices, standards, project management disciplines.Output from gpt-3.5-turbo model
Prompt: "What are the responsibilities of the job? Express the answer in point form."
- Provide technical leadership for data analysis functions
- Analyze and interpret business and data requirements to develop complete business solutions
- Design and implement reporting platforms and complex ETL frameworks
- Work with technology/project teams to ensure data design is fully understood and development initiatives are in line with intended design and standards
- Deliver business or enterprise data deliverables for various platforms/servers/applications/systems
- Provide data analysis and requirements within enterprise platform
- Implement processes aligned to data management standards, ensure data quality and requirements are embedded in/adhered to within system development deliverables
- Develop and maintain knowledge of data available from upstream sources and data within various platforms
- Perform data profiling using TD tooling and ad hoc system query languages to validate data analysis
- Help development and testing teams resolve data issues
- Support the user community by helping them interpret data
- Engage with data managers, stewards and owners to implement, maintain, enhance data governance, quality and related policies, aligning with TD's standards and frameworks
- Ensure capture of requirements related to data privacy and security, governance and access controlsThe output of text-davinci and gpt-3.5-turbo model are very close in quality. The difference in application is that you include a system prompt when using gpt-3.5-turbo since it is a chat model. There are a few difference in what each model consider are responsibilities, with a lot of overlap as well, and some points are the same word for word. The system prompt essentially instructs the AI model what role it subsumes, thus aligning it’s responses closer to what the user intends.
The cheaper text models such as tex-curie, text-baggage, and text-ada are not worth considering. I found the quality of their responses nowhere near the latest text-davinci or gpt-3.5 chat model. Considering the 10x cost difference between the two models for very similar performance, it would be wise to use gpt-3.5-turbo for most applications.
Here are some python scripts for getting started with the api to perform the same tasks:
## Using text-davinci-003 model
davinci_cost = 0.02 # $0.02/1000 tokens
def davinci_completion(prompt, model="text-davinci-003", max_tokens=1000, temperature=0, top_p=1, n=1, stop=None):
response_json = openai.Completion.create(
engine=model,
prompt=prompt,
max_tokens=max_tokens,
temperature=temperature,
n=n,
stop=stop,
top_p=top_p
)
return response_json
def get_responsibilities_davinci(jd, max_tokens=1000, temperature=0, return_all=False):
prompt = 'Tell me the responsibilities or duties of this job description in point form: \n' + jd
response_json = davinci_completion(prompt, max_tokens=max_tokens, temperature=temperature)
text_response = response_json['choices'][0]['text']
cost = response_json['usage']['total_tokens']* davinci_cost/1000
if return_all:
return text_response, cost, response_json
else:
return text_response
def get_qualifications_davinci(jd, max_tokens=1000, temperature=0, return_all=False):
prompt = 'Tell me the qualifications or requirements of the candidate from this job description in point form: \n' + jd
response_json = davinci_completion(prompt, max_tokens=max_tokens, temperature=temperature)
text_response = response_json['choices'][0]['text']
cost = response_json['usage']['total_tokens']* davinci_cost/1000
if return_all:
return text_response, cost, response_json
else:
return text_response## Using gpt-3.5-turbo chat model
chat_cost = 0.002 # $0.002/1000 tokens
def chatcompletion(prompt, model="gpt-3.5-turbo", max_tokens=1000):
response_json = openai.ChatCompletion.create(
model=model,
temperature=0.1,
messages=[
{"role": "system", "content": "You are an assistant that can summarize and parse job descriptions concisely."},
{"role": "user", "content": prompt},
],
max_tokens=max_tokens )
return response_json
def get_responsibilities_chat(jd, max_tokens=1000, temperature=0.1, return_all=False):
user_prompt = 'What are responsibilities or duties of this job description. Write the response in point form: \n' + jd
response_json = chatcompletion(user_prompt, max_tokens=max_tokens, temperature=temperature)
text_response = response_json['choices'][0]['message']['content']
cost = response_json['usage']['total_tokens'] *chat_cost/1000
if return_all:
return text_response, cost, response_json
else:
return text_response
def get_qualifications_chat(jd, max_tokens=1000, temperature=0.1, return_all=False):
user_prompt = 'What are the qualifications or requirements of the candidate from this job description in point form: \n' + jd
response_json = chatcompletion(user_prompt, max_tokens=max_tokens, temperature=temperature)
text_response = response_json['choices'][0]['message']['content']
cost = response_json['usage']['total_tokens'] *chat_cost/1000
if return_all:
return text_response, cost, response_json
else:
return text_response# extracting responsbilities and qualifications from job descriptions
df_jobs['responsibilities'] = df_jobs['job_description'].apply(get_responsibilities_chat)
df_jobs['qualifications'] = df_jobs['job_description'].apply(get_qualifications_chat)Performance and cost:
The cost of each model can be found here https://openai.com/pricing. At the time of this writing, text-davinci costs $0.02/1000 tokens and gpt-3.5-turbo costs $0.002/1000 tokens, making the former model 10x more expensive. I didn’t get a chance to use gpt-4 models, but it will be interesting to see the difference in performance.
The average job description is about ~1000 tokens. The API also charges text generated, which can be capped by the max_tokens parameter. On average, the generated response is about ~200 tokens, which is about ~1200 tokens used per prompt. Applying the functions for extracting responsibilities and qualifications (see python code below) using gpt-3.5-turbo model for 100 job descriptions will cost:
2 x 1200 tokens x ($0.002/1000 tokens)= $0.048
In other words, $0.48 per 100 job descriptions.
Limitations
*This section was written by ChatGPT after copying and pasting the above post. Since it was written so well (almost too well, scary…), I decided to include it. It is interesting how the model is fully aware of it’s own limitations.
While GPT models have shown impressive results, they do have certain limitations. Some of the limitations that you should be aware of when using GPT for job description analysis are:
- Inconsistency: GPT models may sometimes generate inconsistent responses or summaries for different parts of the job description.
- Overfitting: When generating summaries, GPT models might overfit on certain phrases or terms and may repeat them unnecessarily, leading to less meaningful summaries.
- Lack of understanding: GPT models are great at identifying patterns and generating human-like text, but they do not truly understand the meaning behind the text. This can result in summaries that may not accurately capture the essence of the job description.
- Ambiguity: Since job descriptions can be vague or ambiguous, the GPT models may struggle to extract the most relevant information from them. They may also generate ambiguous or unclear summaries in such cases.
- Bias: GPT models can sometimes exhibit biases present in the training data. These biases may be reflected in the generated summaries, which could be a potential concern.
To overcome these limitations, you can:
- Manually review the generated summaries to ensure their accuracy and relevance.
- Experiment with different prompt styles or instructions to obtain better results.
- Train custom models that are specifically fine-tuned for job description analysis tasks, which may yield better results than using general-purpose GPT models.
- Combine GPT-generated summaries with other techniques, such as keyword extraction or topic modeling, to improve the overall quality of the analysis.
- Continuously update and refine your analysis approach based on feedback and new information, as the job market landscape evolves over time.
In conclusion, using GPT models like GPT-3.5 Turbo to analyze job descriptions can be a cost-effective and powerful way to gain insights into the job market landscape. However, it is essential to be aware of the limitations and employ best practices to obtain the most accurate and relevant results.
